Quick Detour to Make Sure my Plant's OK
Between lots of travel and language projects lately, I’ve not had a ton of time to write code, so I solved a little non-problem this weekend: I can see the current soil hydration level of my one house plant so I have a more informed idea of when to water it (or maybe trigger a dumb automation).
I think it’s the kind of simple project that other people might want to apply to some other data source, but maybe don’t know where to start. If that’s you, I’m planning to write this blog post for the purpose of being a guide for writing a very similar application that’s not super robust, but gets the job done.
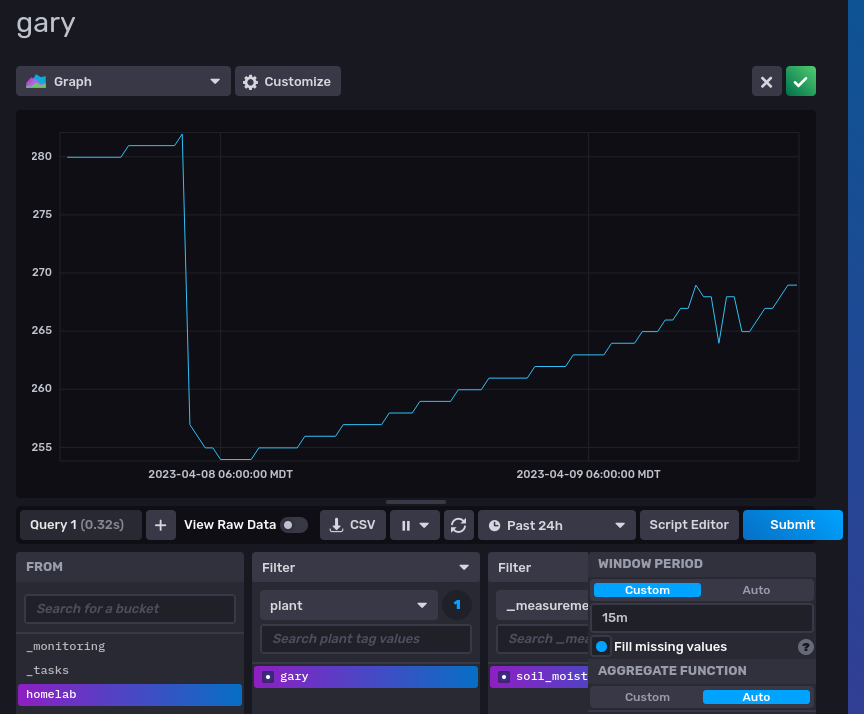
Sneak peak at the result:
Arduino Code
First there’s the Arduino code, which is best when it’s very simple. In my case, I’m reading one sensor and writing the data out periodically over the serial port.
#include "Arduino.h"
constexpr uint8_t READINGS_PER_CYCLE(5);
void setup() {
Serial.begin(9600);
while (true) {
uint8_t header[3] = {0xAA, 0xAA, 0xAA};
Serial.write(header, 3);
for (auto i = 0u; i < READINGS_PER_CYCLE; ++i) {
uint16_t data = analogRead(A0);
uint8_t data_arr[2] = {(data >> 8) & 0xff, data & 0xff};
Serial.write(data_arr, 2);
}
delay(5000);
}
}
void loop() {}
In order to solve the annoying problem of reading mid-buffer and not being sure
where in the byte sequence the frame is, I’ve added a prefix of 0xAA, 0xAA, 0xAA
to the start of each message. Since the Arduino has a 10-bit ADC, it can never
produce a value of 0xAAAA from the sensor, so this seemed safe and makes a nice
pulse train for auto-baud detection. Then I stuff the bytes into arrays of 2 bytes
and send them individually, big endian (higher byte first).
This wraps up the sensor code, at which point I plugged the Arduino into my server and let it run.
InfluxDB
On my server, I set up InfluxDB to run via a docker compose file such that it will be restarted every time the server restarts:
version: "3.9"
services:
influxdb:
image: "influxdb:2.0"
container_name: "influxdb"
restart: unless-stopped
ports:
- "8086:8086/tcp"
volumes:
- $HOME/influxdbv2:/root/.influxdbv2
Once you run it the first time, you can create a login, an organization name, and an initial bucket to put your data in. You should also make sure to copy down your access token and stick it in your favorite password vault. We’ll need all of these things later.
Serial to Database
I wrote a tiny program that is designed to run on the server that’s mostly an amalgamation of
two examples from tokio_serial and influxdb2. There’s a litany of imports:
// To generate timestamps
use chrono::Utc;
// The influxdb2 crate takes an async streaming iterator for some reason
use futures::prelude::*;
// Influx client and a trait for serializing the data to send to the database
use influxdb2::Client;
use influxdb2_derive::WriteDataPoint;
// Traits for reading bytes from the serial port
use tokio::io::AsyncReadExt;
use tokio_serial::SerialPortBuilderExt;
The data point here has to implement the trait WriteDataPoint and it’s important to add a tag
for the data plant which I’m using as the name, then the timestamp (which may be possible to
omit in which case it will use the current time as default), and finally the actual datapoint
which is a field. If you miss the measurement = "your_name" attribute here, it will use the
name of the struct.
#[derive(Default, WriteDataPoint)]
#[measurement = "soil_moisture"]
struct SoilMoisture {
#[influxdb(tag)]
plant: String,
#[influxdb(field)]
value: u64,
#[influxdb(timestamp)]
time: i64,
}
Initializing the serial port and the Influx database client is mostly just a bunch of hardcoded
literals, you’ll want to substitute in the path where your Arduino’s serial port is mounted
(probably /dev/ttyACM0 or /dev/ttyUSB0, but the number might be incrementing). This path can
technically change based on what’s plugged in and in what order, I’ll leave it as an exercise to
the user to figure out how to set up the udev related files to make it consistent.
The parameters for the InfluxDB destination are mostly hardcoded. I copied my access token into
an environment variable in my ~/.bashrc to avoid committing it to version control. My database
isn’t currently on the public internet, but better to not even when we’re doing a lazy version.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let tty_path = "/dev/ttyACM0";
let mut serial_port = tokio_serial::new(tty_path, 9600).open_native_async()?;
serial_port.set_exclusive(false).unwrap();
let org = "snostorm";
let bucket = "homelab";
let influx_url = "http://localhost:8086";
let token = std::env::var("INFLUXDB2_TOKEN").unwrap();
let client = Client::new(influx_url, org, token);
// ... snip ...
}
Next is the actual main loop that needs to track the state of the frame that’s been sent so that
the program ensures it reads an entire frame before trying to process the data. I could’ve made
this a little easier on myself by changing how I wrote the serial writing on the Arduino side, but
it’s much easier to remotely deploy new code to the server, so the complexity is here. Basically,
the program shifts the frame start until it’s pointing at the frame sequence [0xAA, 0xAA, 0xAA]
and we’ve ensured we’ve received enough data (13 bytes = 3 byte header + (5 * 2 byte sample)).
This undoubtedly has some bugs, but it is reading the data accurately enough for now so I can fix
it later.
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// ... snip ...
let mut read_buffer = [0u8; 256];
let mut bytes_read = 0;
let mut frame_start = 0;
loop {
if let Ok(n_bytes) = serial_port
.read(&mut read_buffer[frame_start + bytes_read..])
.await
{
bytes_read += n_bytes;
while bytes_read >= 3
&& &read_buffer[frame_start..=frame_start + 2] != &[0xAA, 0xAA, 0xAA]
{
// Adjust the counters forward to "delete" the trailing message already
// in the serial buffer
bytes_read -= 1;
frame_start += 1;
}
// After verifying we're starting at the frame start, make sure we've got
// the whole message
if (bytes_read - frame_start) >= 13
&& &read_buffer[frame_start..=frame_start + 2] == &[0xAA, 0xAA, 0xAA]
{
// ... snip ...
} else {
// I get a lot of these, which means there's some bugs here
eprintln!(
"Uh oh, mid-sequence... And I'm lazy...\n{:x?}",
&read_buffer[frame_start..frame_start + bytes_read]
);
}
// Probably not necessary since we're using async, but whatever
tokio::time::sleep(tokio::time::Duration::from_secs(4)).await;
}
}
}
For deserializing the data, I’m just doing the byte manipulation manually, reversing the logic
from the Arduino code. The first map extracts each measurement into it’s own [u8; 2] slice,
then the second assembles that back into a u16. Finally it’s all collected into a Vec<u16>.
I sort and take the median here to guard against noise on the cable and/or other sources of
error in the Arduino measurement. Not super robust, but it seems to work. I pair that with a
filter for values that aren’t possible to be generated by an Arduino’s 10-bit ADC (max of 0x3ff).
if (bytes_read - frame_start) >= 13
&& &read_buffer[frame_start..=frame_start + 2] == &[0xAA, 0xAA, 0xAA]
{
let measure_start = frame_start + 3;
let mut measurements = (0..5)
.into_iter()
.map(|id| &read_buffer[(measure_start + 2 * id)..=(measure_start + 2 * id + 1)])
.map(|measurement_raw| {
((measurement_raw[0] as u16) << 8) + (measurement_raw[1] as u16)
})
.collect::<Vec<_>>();
measurements.sort();
let median = measurements[2];
bytes_read = 0;
frame_start = 0;
if median > 0x3ff {
continue;
}
// ... snip ...
}
Finally, we stuff that calculated median into the InfluxDB by constructing an instance of the
SoilMoisture struct
if (bytes_read - frame_start) >= 13
&& &read_buffer[frame_start..=frame_start + 2] == &[0xAA, 0xAA, 0xAA]
{
// ... snip ...
let points = vec![SoilMoisture {
plant: "gary".into(),
value: median.into(),
time: Utc::now().timestamp_nanos(),
}];
if let Ok(..) = client.write(bucket, stream::iter(points)).await {
println!("Writing data... {}", median);
}
}
The final problem to solve is how to get it to run on the server. Unlike the influxdb container,
I’ve not made a Docker container for running this because, again, I’m lazy. Instead I can just
run a byobu shell which will persist even if you log out of your SSH session, but it will not
auto-restart if the server is restarted, so that’s a problem to solve for another day.
So, in a byobu shell:
$ cargo build
...
$ target/debug/<executable-name>
There’s lot to fix to make this convenient, but for now I’ve got data on a dashboard and that’s good enough for a quick weekend project.
If you notice a dead link or have some other correction to make, feel free to make an issue on GitHub!